



Overview
In the last decade, the world has witnessed a steep rise in the technology sector, specifically the smartphone market, with devices becoming significantly more advanced each year. This rapid expansion has resulted in an equal explosion within the mobile app market. The mobile app market has skyrocketed due to various functionalities and needs in different sectors and categories, i.e. lifestyle, fitness, gaming, automotive fields, legal, etc. With such a vast catalog of mobile applications and numerous ways of monetizing them and related functionalities, keeping track of and performing maintenance on such a diverse set of data sources and data formats can become expensive, time consuming, and lack operational excellence. In such a situation, integrating a program such as RevenueCat allows consumers to build a centralized hub for monetary and subscription-based data.

RevenueCat 101
RevenueCat is a subscription platform for mobile apps that provides functionality to connect it to your developed mobile applications to track, maintain and analyze subscription and monetary data for applications from both the Apple App Store and the Google Play Store. RevenueCat provides a singular data format output regardless of the storefront from which the app was downloaded, which makes it easier to consume by a platform, program or person.
The Challenge
While RevenueCat and other such platforms make it easier to track and attain subscription and monetary data for an application, efforts still have to be put in to acquire a generalized report that anyone can utilize with ease. For instance, when RevenueCat provides a datafile delivery, that file must first be downloaded, checked for data redundancies and duplications, imported into a reporting program, and be transformed into a report everytime the process is repeated. One of our clients who faced this problem approached us while searching for a solution to minimize manual tasks and time consumption all while needing additional manpower.
Data Pipeline Automation
Our team at SC&H proposed and developed a solution to develop a seamless automated data pipeline that would allow our client to acquire an up-to-date visual report every day without manual effort. The data pipeline leveraged the integrational capabilities of RevenueCat, AWS (Amazon Web Services), PostgreSQL, Python, and PowerBI. AWS provides a diverse pool of services and tools while PostgreSQL running on Amazon RDS allows for cost-efficient and scalable database implementations in the cloud.
At a high level, the following is a visual representation of the developed automated data pipeline:
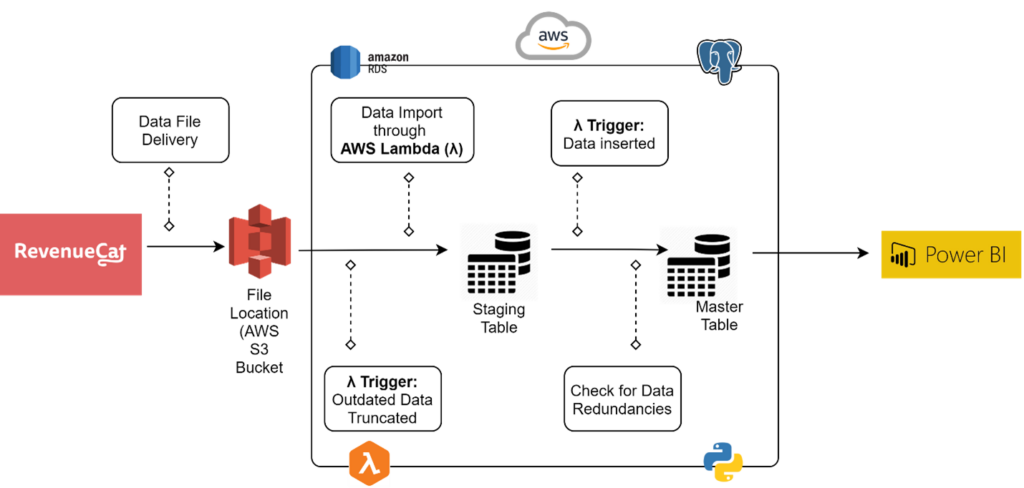
Below are brief sequential details of each step involved in the development of the automated data pipeline:
- Setting up RevenueCat: Once an app has been published to the respective app store and the application has been configured in the storefront, RevenueCat provides options and packages to register the mobile app with the platform to initiate datafile generation.
- ETL Exports: RevenueCat allows you to automatically receive data files on a daily basis through a cloud storage provider, i.e. Amazon S3 or Google Cloud Storage. An Amazon S3 bucket was set up as the data file storage point with assigned access policies and security.
- Database Setup: Two tables, a staging table and a master table, were created in the PostgreSQL database through Amazon RDS in order to hold the imported data from the files received in the S3 bucket.
- AWS Lambda(λ): An AWS lambda function was utilized to automatically convert scripts to python in response to an event i.e. import or update of the data file in the S3 bucket. The lambda function had the following specifications and responsibilities.
The lambda function was set up based on Python code, SQL queries, and used the following packages:- Boto3: An AWS Python software development kit (SDK) that enables developers to write code that works with other Amazon web services such as S3 or an EC2 instance.
- Psycopg2: Acts as an adaptor for Python programming language and allows the implementation of different python specifications.
- OS: Allows utilization of system dependent functions.
- StringIO: Offers a simple way to use the file API to deal with text.
- An event trigger based on the import or update of the data file allowed the lambda function to clear the staging table prior to populating it and then copy the data to the master table. This was done while checking for data redundancies and inconsistencies through a combination of columns and fields used as a unique identifier to accurately store unique records while removing any duplicates.
- PowerBI: A live connection was established between the PostgreSQL (AWS RDS) master table and PowerBI to acquire data and perform required transformations and calculations using DAX in PowerBI Desktop. Dashboards holding insightful and interactive visuals/reports were created to perform mobile application financial/subscription data analysis, follow trends, forecasting, and managerial reporting purposes. An App Workspace holding a data dictionary, BI dashboards, and related documents was setup on PowerBI Service as a centralized hub for all reporting needs. The finalized product, utilizing row-level security, held reports and visuals which were accessible based on cooperate hierarchy and respective organizational status.
Our Expertise
At SC&H, we believe that with quintillions of bytes of data generated regularly and global trends moving toward automation and AI, the need for automated solutions and seamless data pipelines is growing rapidly. Our team’s experience with data-driven organizations, along with the latest technological tools and platforms will guide your organization to make cost-efficient and accurate business decisions. Reach out to our team→





