



In today’s data driven world, for organizations with enormous datasets generated from diverse sources, data management can be expensive and time consuming. Hence, organizations look toward efficient methods to lower costs and enhance operational performance. At the root of the essential data infrastructure, is a data pipeline that allows a smooth transfer of data between different applications and platforms. Such a seamless stream of data enables an organization to improve business intelligence and data mobility, enhancing the effectiveness and efficiency of corporate decision-making in a data-driven company culture.
The Business Challenge
One of our clients needed a solution that would allow the organization to export customer communication data from a third-party service provider, import the data into a database, and finally establish a connection between the database and Power BI in order to transform the data and create meaningful visuals, all done in an automated manner. Initially, the organization was performing all such tasks manually along with incrementally storing the data on a hard drive adding to time consumption and required manpower.
The Solution
We leveraged Amazon Web Services’ (AWS) cloud infrastructure & PostgreSQL as important intermediaries to establish the automated connection between the third-party service provider and Power BI. For many businesses and start-ups, PostgreSQL has become a popular open-source relational database while Amazon RDS allows cost-efficient and scalable PostgreSQL implementation in the cloud.
By utilizing AWS’ cloud infrastructure & PostgreSQL, our team designed the following solution:
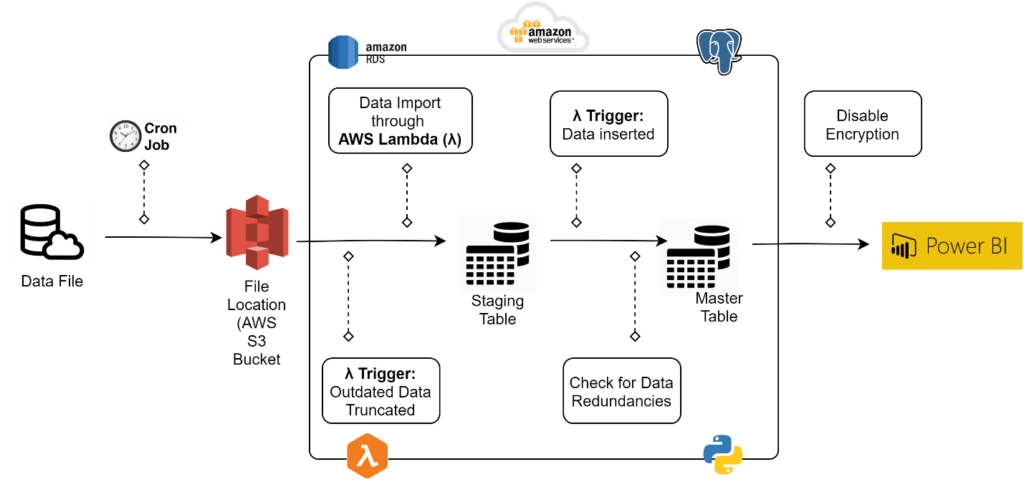
- Ingestion: A Cron Job was set up in order to collect and import data from the 3rd party service provider and store it in a fixed location.
- Amazon S3: An amazon S3 bucket was used as the storage point after the Cron Job.
- Database Table Setup: Two tables, a staging table and a master table, were created in the PostgreSQL database in order to hold the imported data.
- AWS Lambda(λ): An AWS lambda function was utilized to automatically run code in response to an event i.e. import or update of the data file in the S3 bucket. The lambda function had following specifications and responsibilities:
- The lambda function was setup based on Python code, SQL queries, and used the following packages:
- Boto3: An AWS Python software development kit (SDK) that enables developers to write code that works with other Amazon web services such as S3 and EC2 instance.
- Psycopg2: Acts as an adaptor for Python programming language and allows implementation of different python specifications.
- OS: Allows utilization of system dependent functions.
- StringIO: Offers a simple way to use the file API to deal with text.
- The lambda function was setup based on Python code, SQL queries, and used the following packages:
- An event trigger based on import or update of the data file allowed the lambda function to clear the staging table prior to populating it and then copy the data to the master table while checking for data redundancies and inconsistencies.
- Power BI: A connection between PostgreSQL database and Power BI was established that allowed data transformations and creation of insightful data visualizations. Moreover, a periodic data refresh was set in place to update the visuals according to the most up-to-date data in the database.
At SC&H, we believe that with quintillion bytes of data created regularly, the necessity for automated solutions is growing every day. Our experience with data-driven organizations, along with the latest technological tools and platforms will help your organization make cost-efficient accurate business decisions. If you would like to discuss implementing a data pipeline that cuts back on time and increases your team’s efficiency, contact our Data Analytics team today.




